Lujun LI (李路军)
Ph.D. candidate in Hong Kong University of Science and Technology (HKUST)
Clear Water Bay Peninsula, New Territories, Hong Kong
lilujunai@gmail.com, lliee@ust.hk
Ph.D. candidate in Hong Kong University of Science and Technology (HKUST)
Clear Water Bay Peninsula, New Territories, Hong Kong
lilujunai@gmail.com, lliee@ust.hk
I am currently a final-year Ph.D. candidate in HKUST, supervised by Prof. Yi-Ke Guo (Provost & Fellow of REng|HKEng|IEEE).
My research focuses on advancing Efficient Machine Learning and Large Language Models to make AGI smaller, faster, greener and cheaper via novel compression techniques:
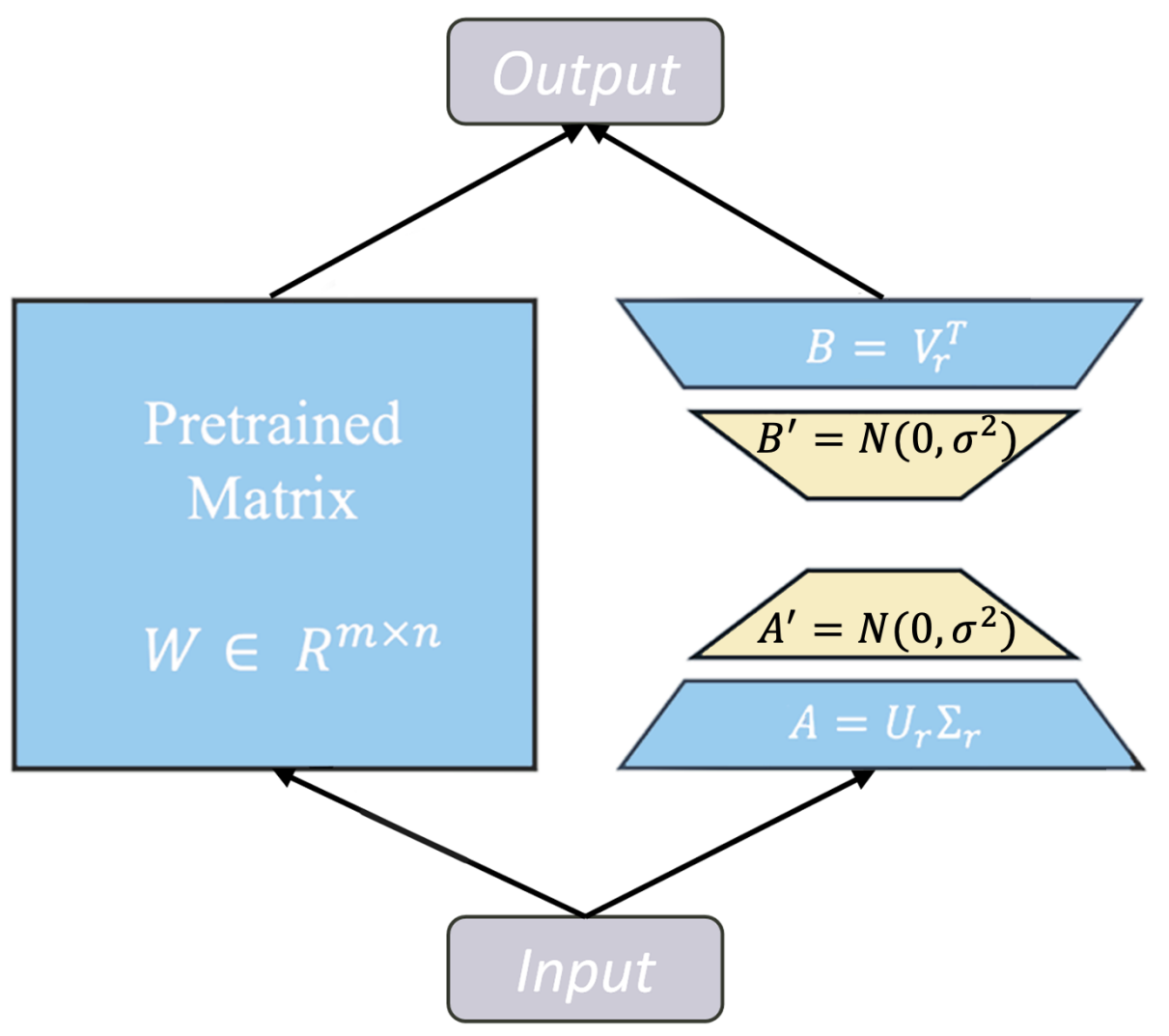
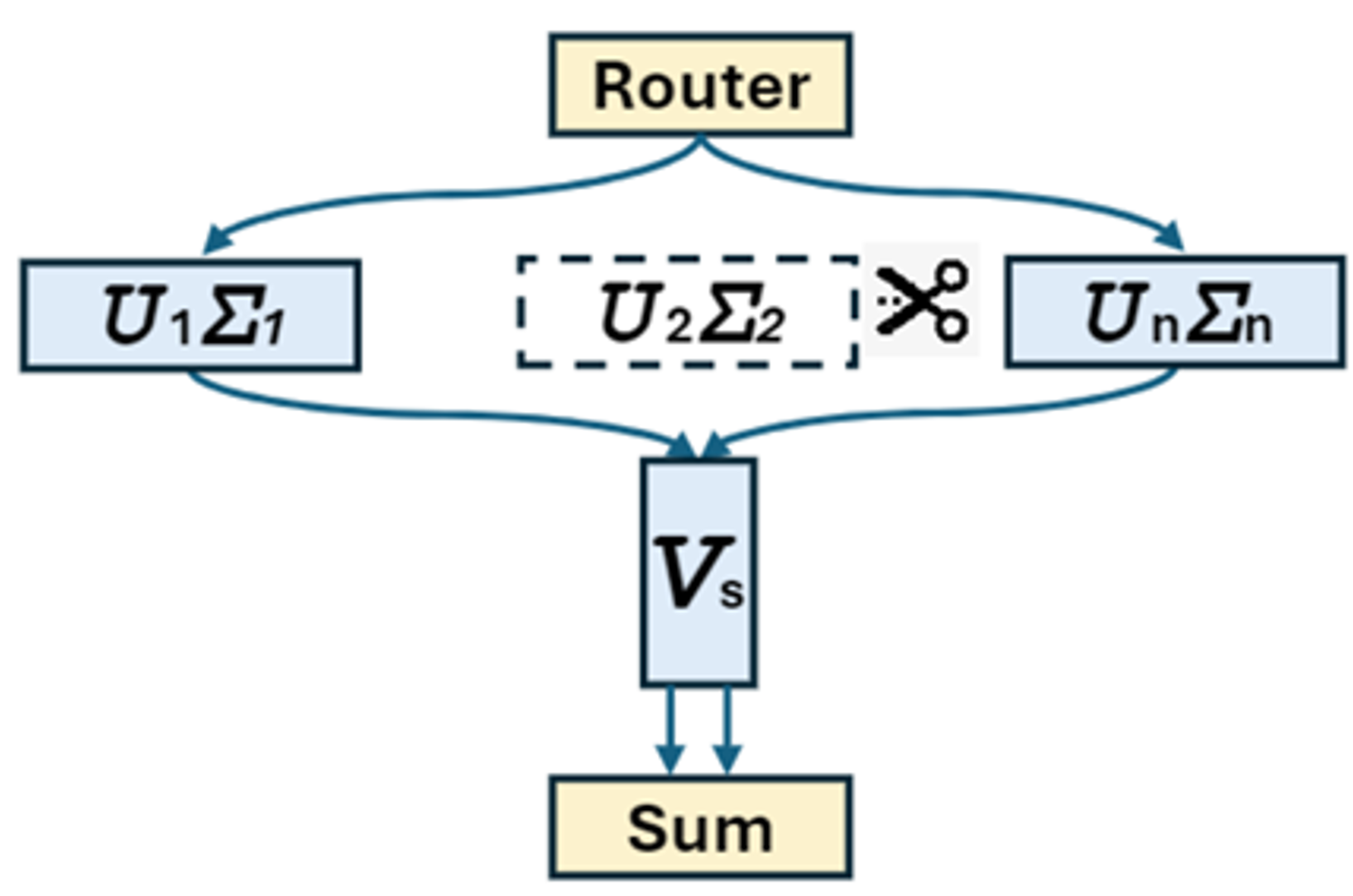
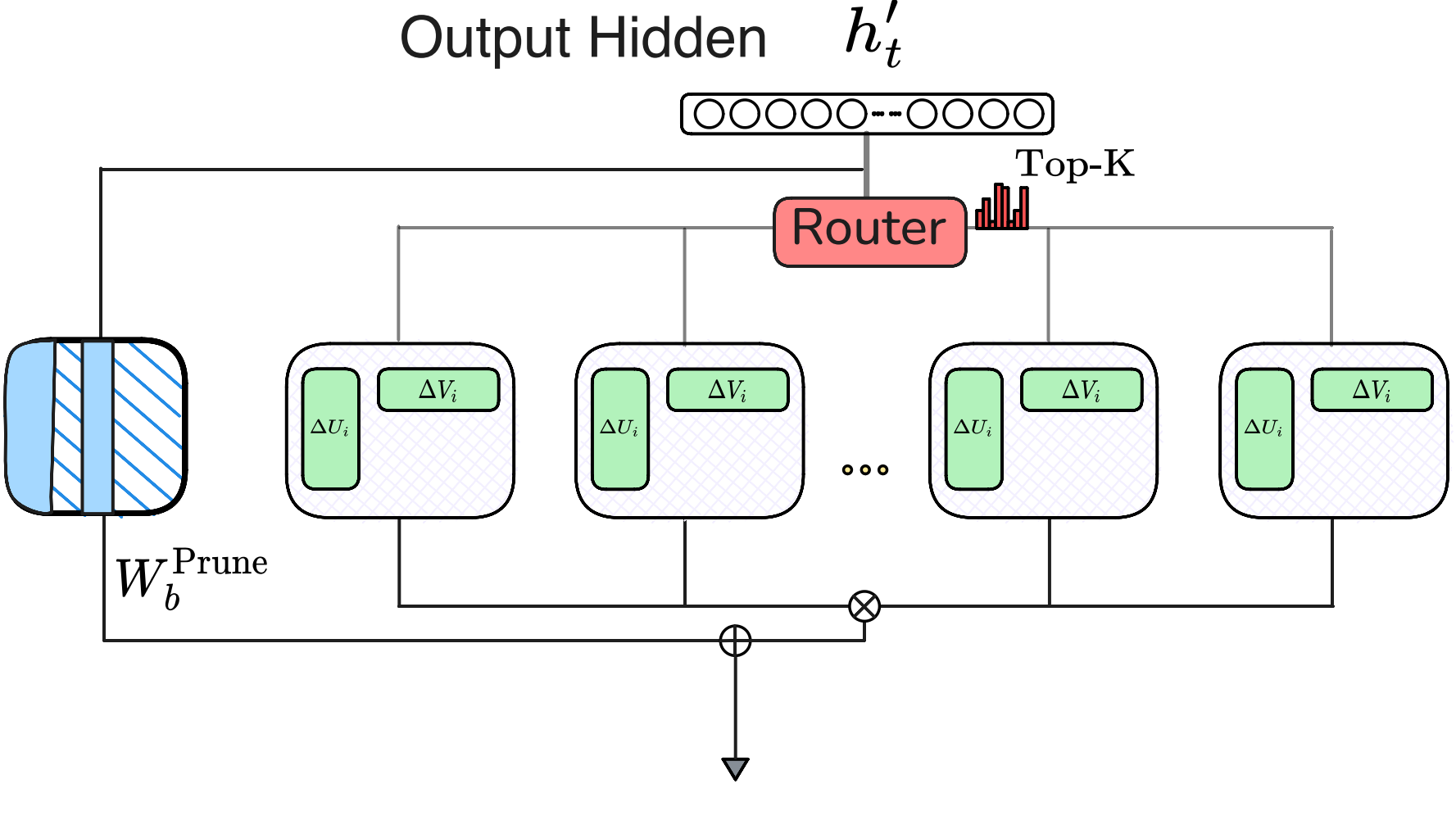
Efficient Mixture-of-Experts (MoE): MoE-SVD (ICML'25), D2-MoE (ICML'25), Sub-MoE (AAAI'26)
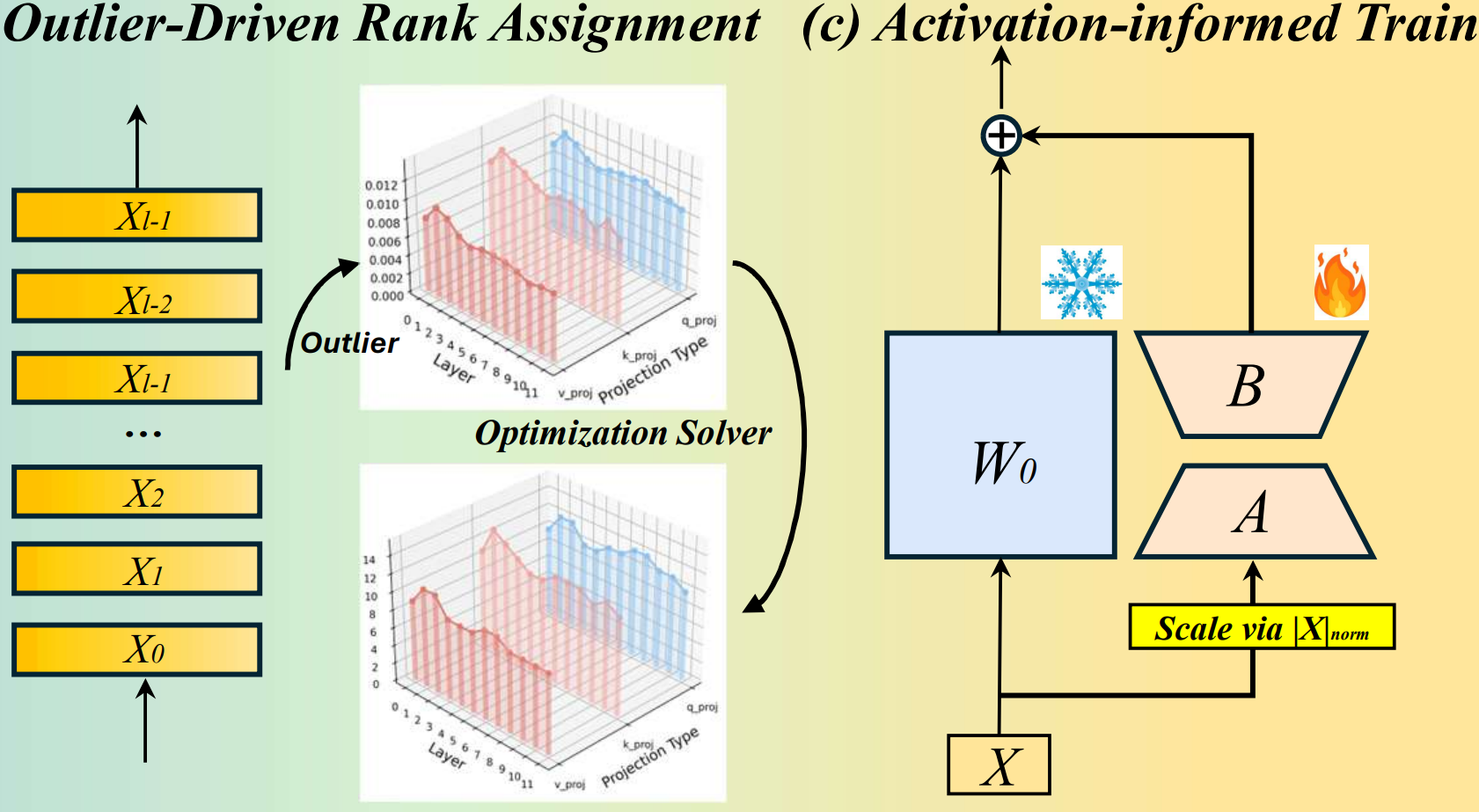
Efficient LLM Fine-tuning: NoRA (ICCV'25), AIRA (ICCV'25)
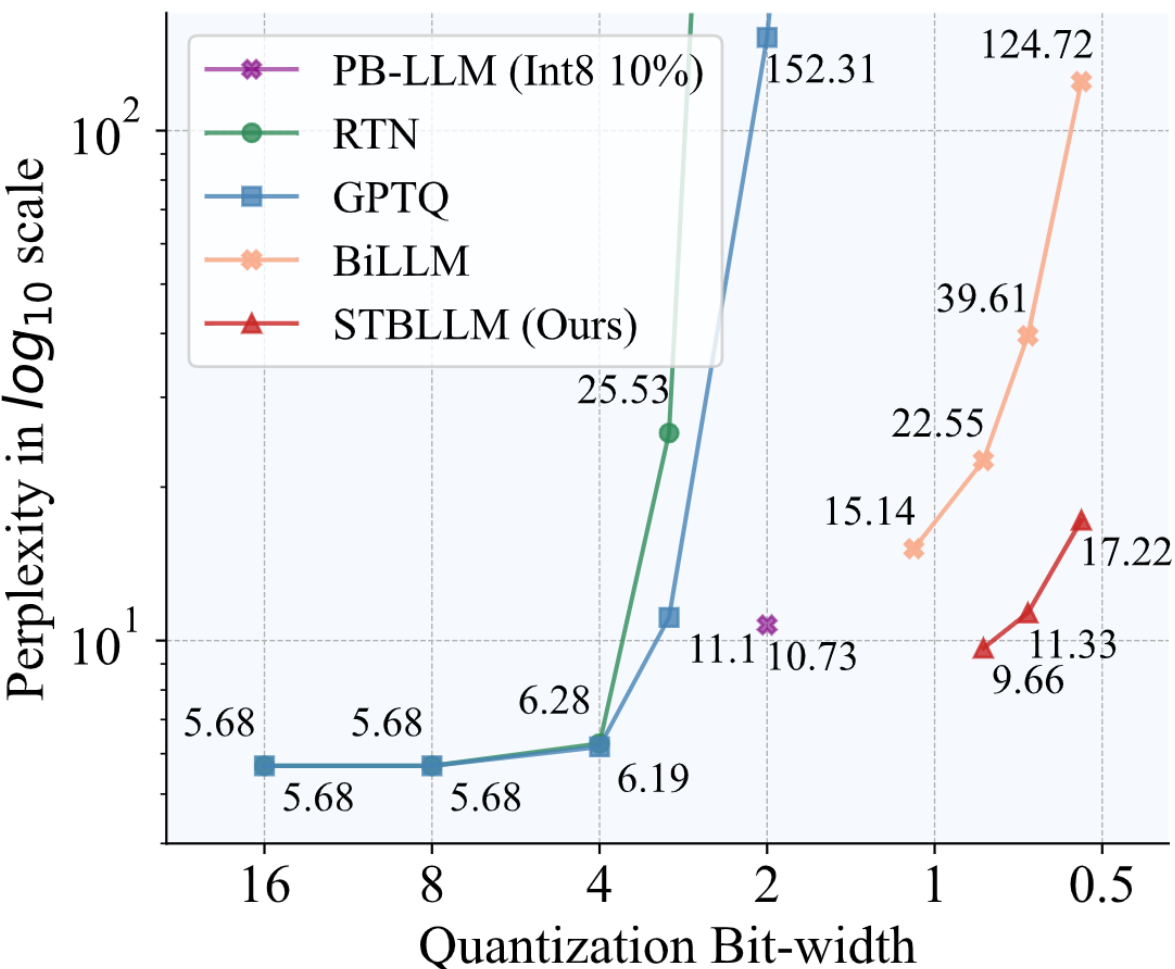
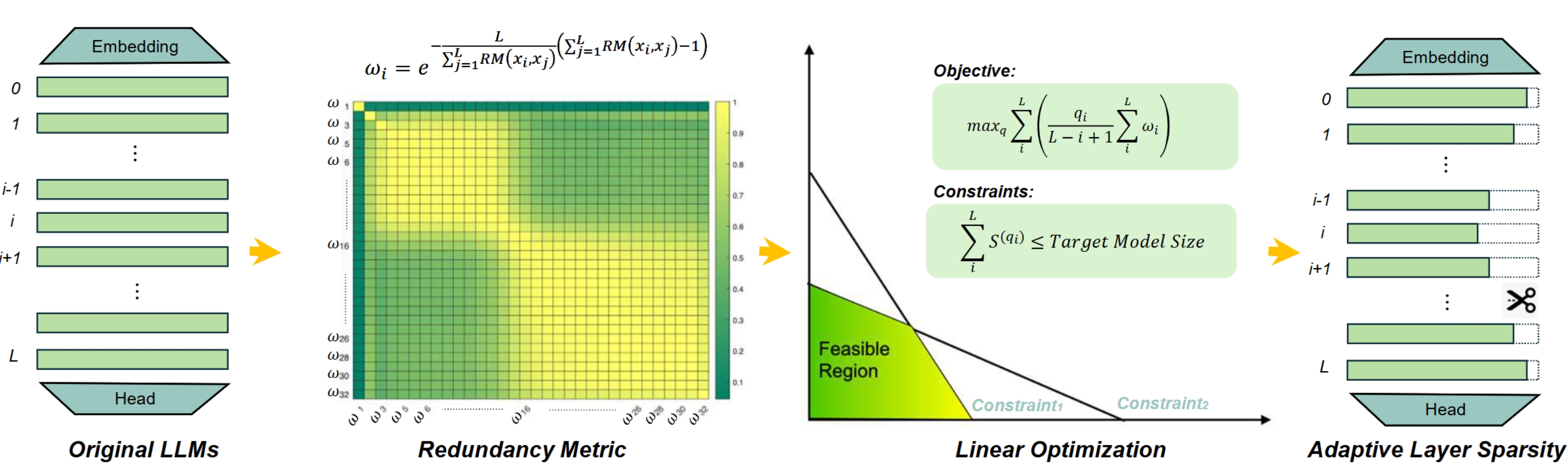
Efficient Large Language Models: Pruner-Zero (ICML'24), DSA (NeurIPS'24), ALS (NeurIPS'24), STBLLM (ICLR'25)
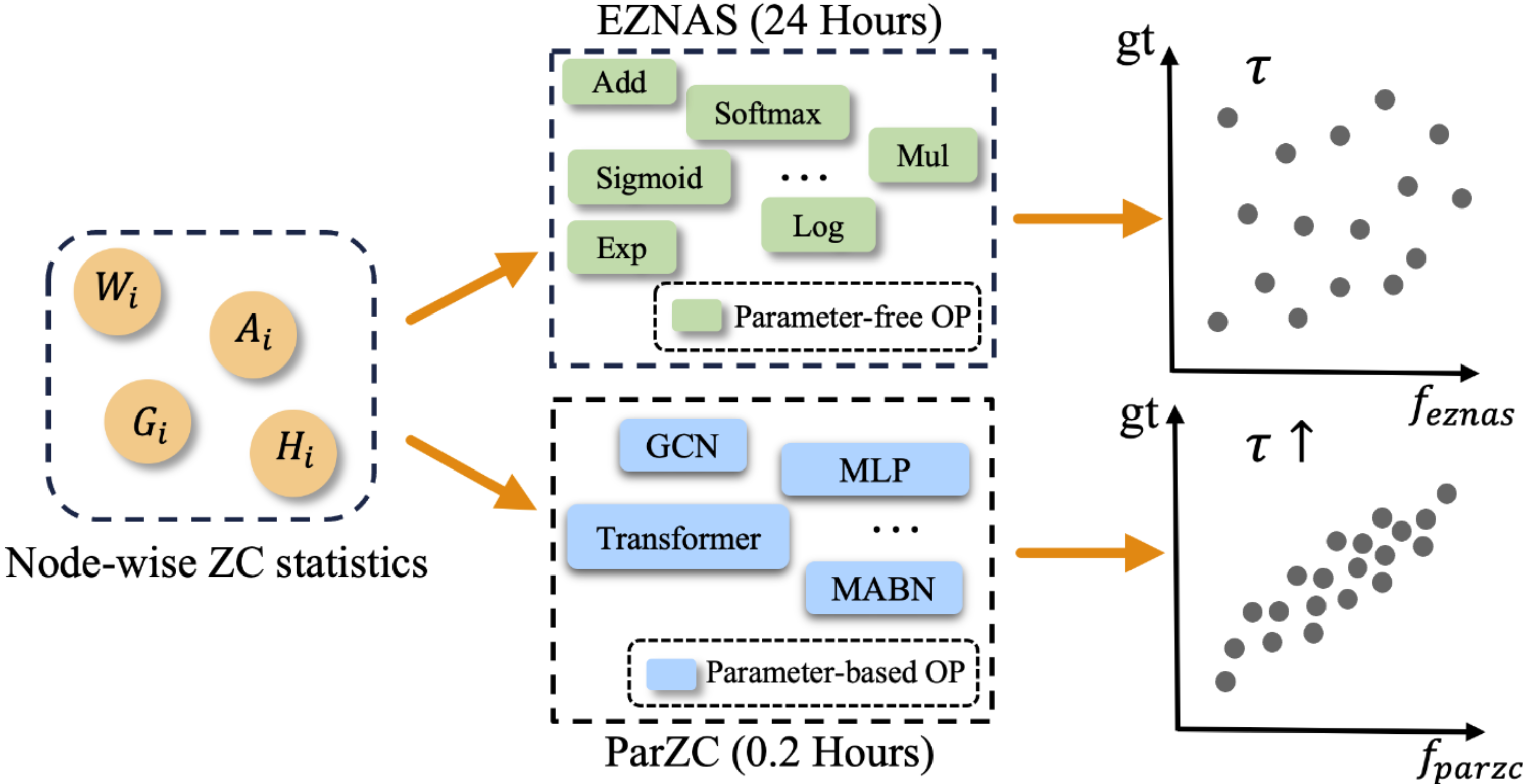
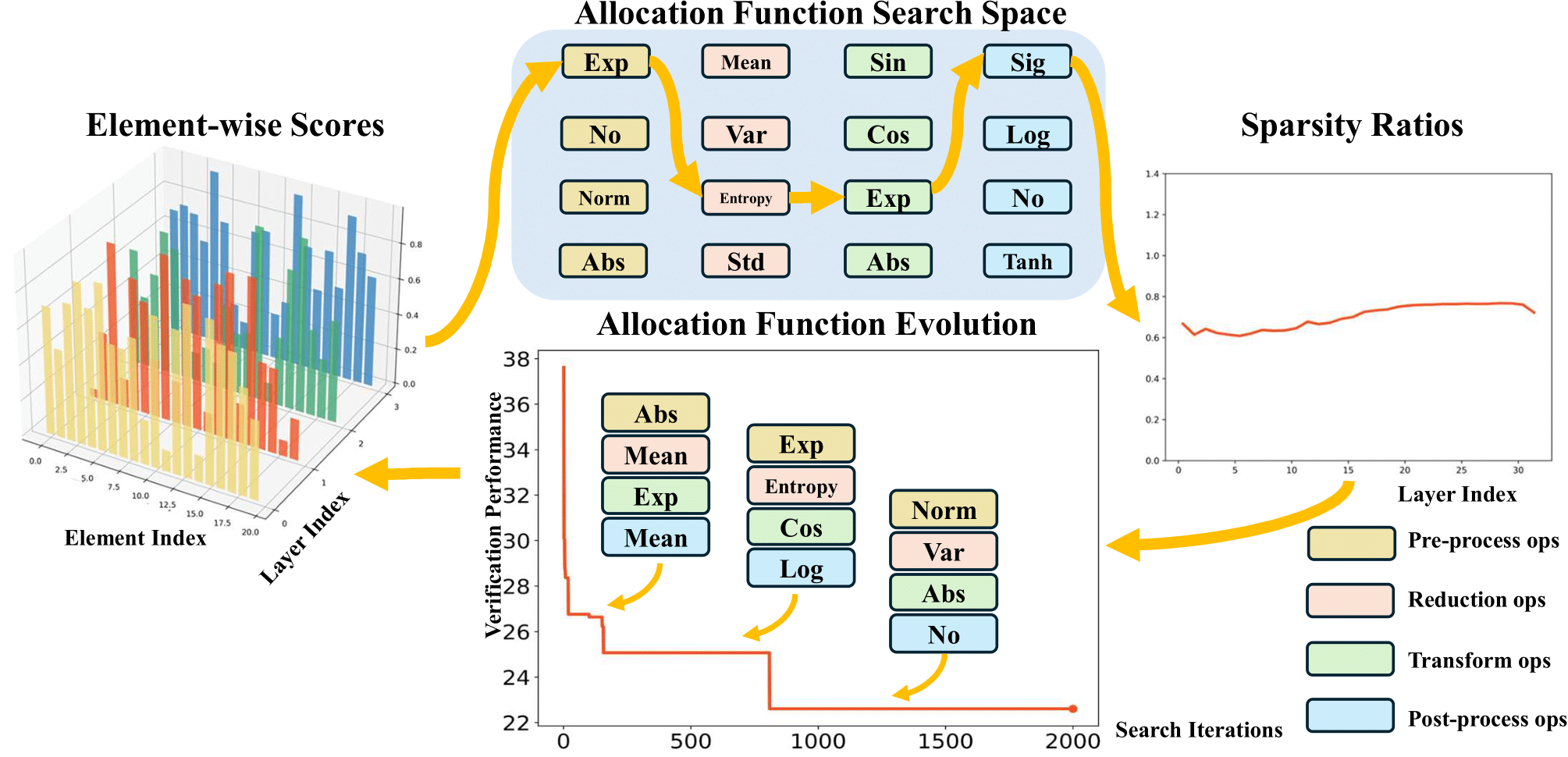
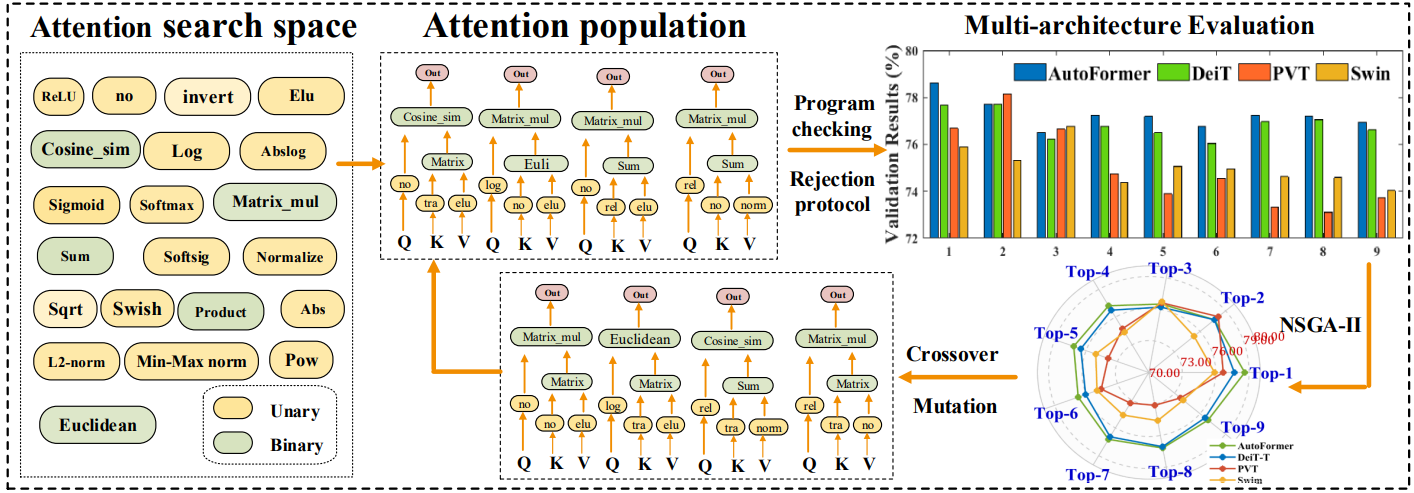
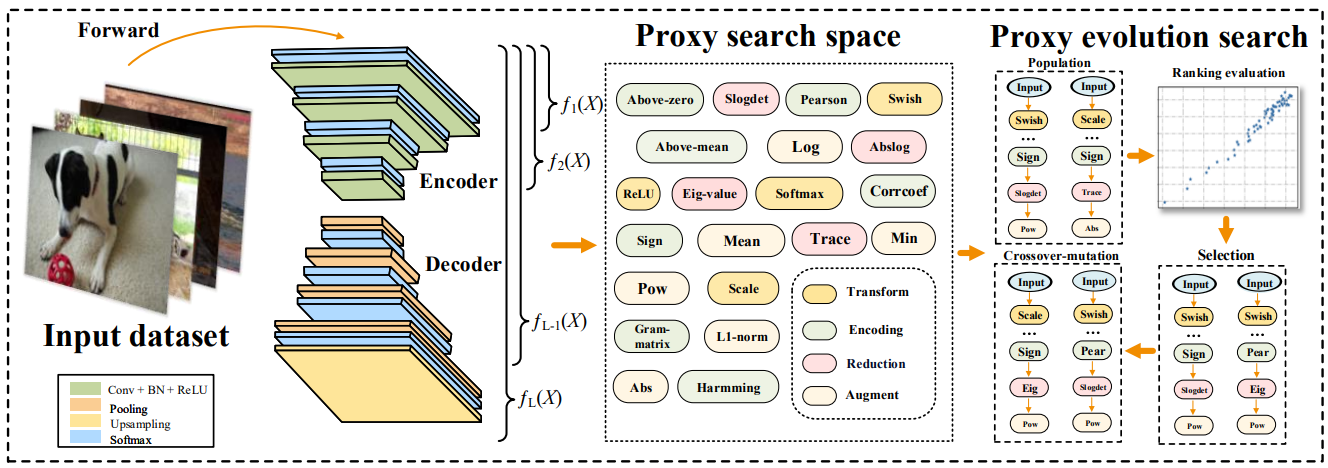
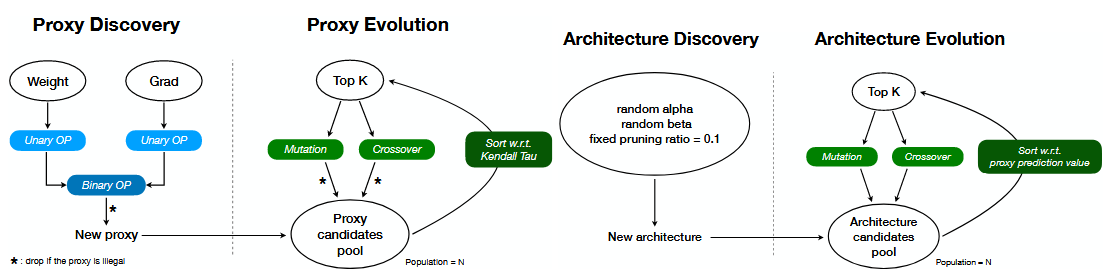
Automated Efficient ML: EMQ (ICCV'23), ParZC (AAAI'25), AutoProx (AAAI'23), SasWOT (AAAI'23), Auto-GAS (ECCV'24), AttnZero (ECCV'24)
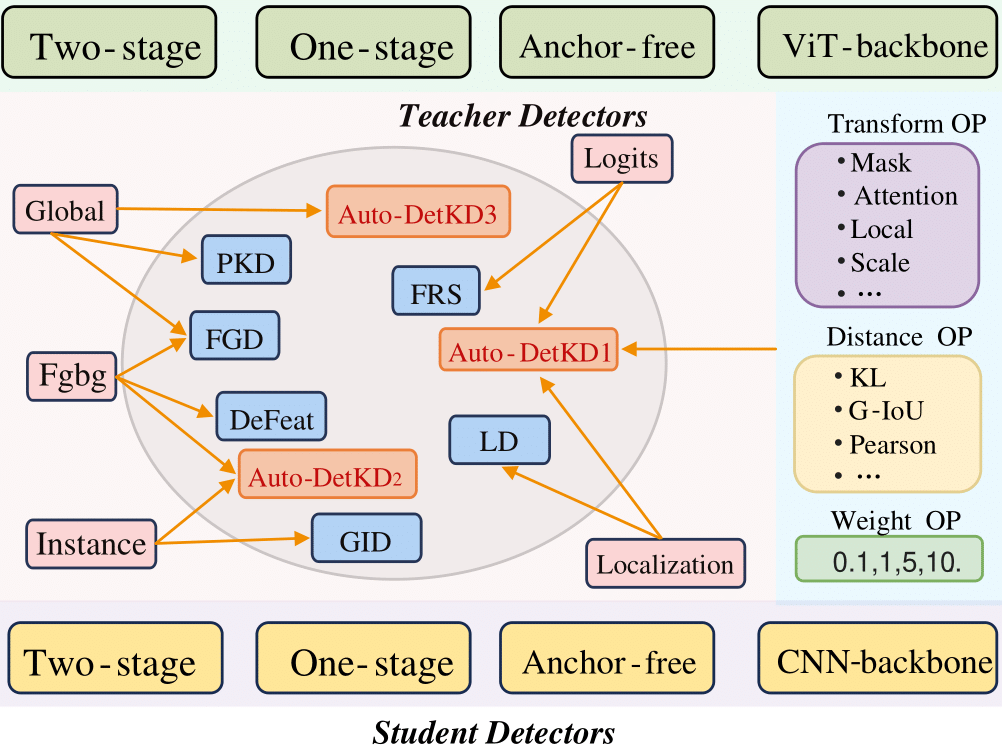
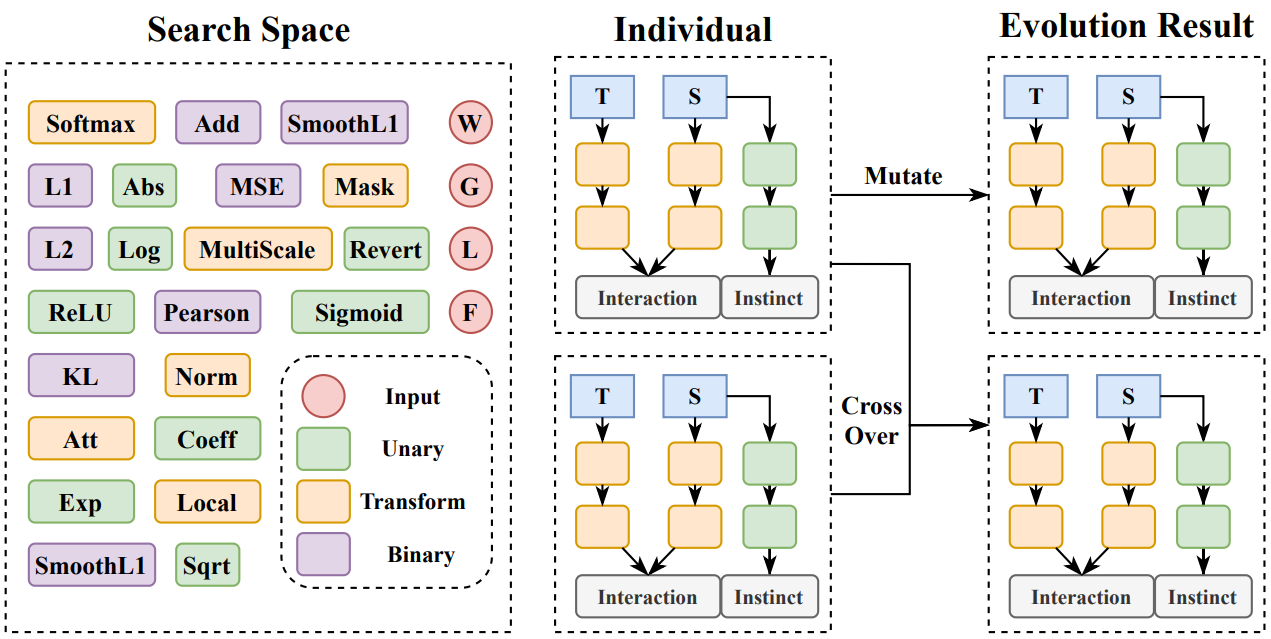
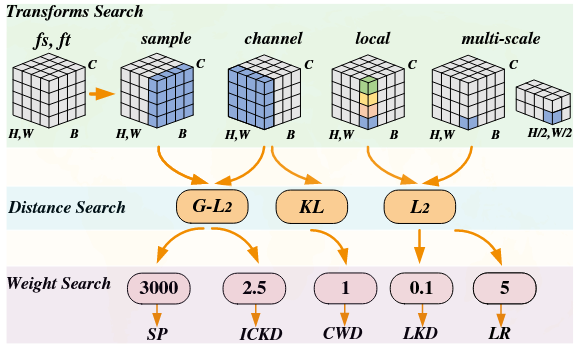
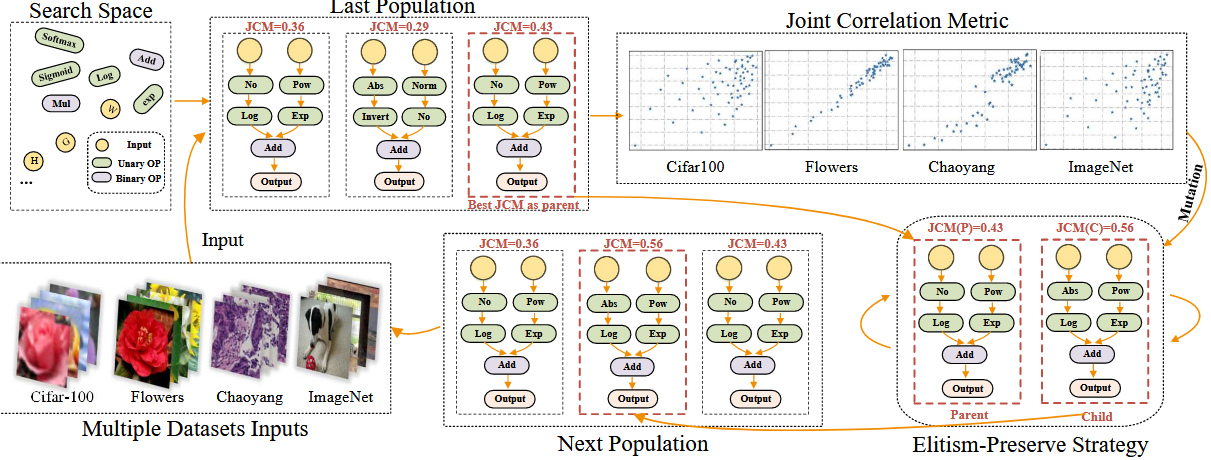
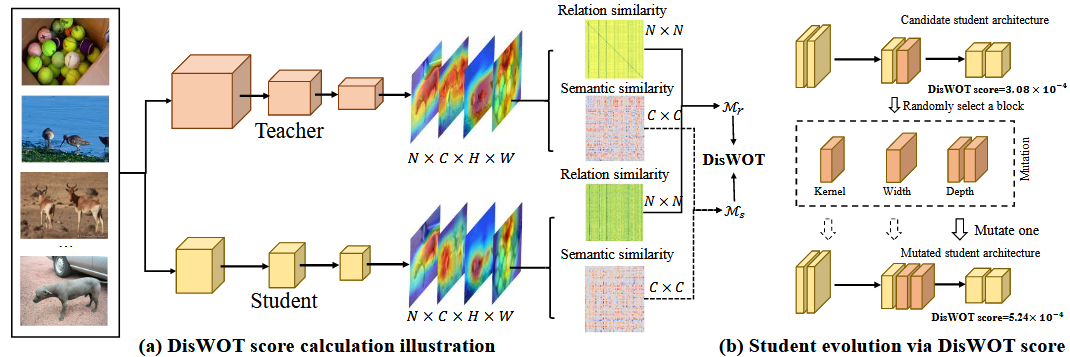
Automated Distillation: DisWOT (CVPR'23), Auto-KD (ICCV'23), KD-Zero (NeurIPS'23), DetKDS (ICML'24), Auto-DAS (ECCV'24)
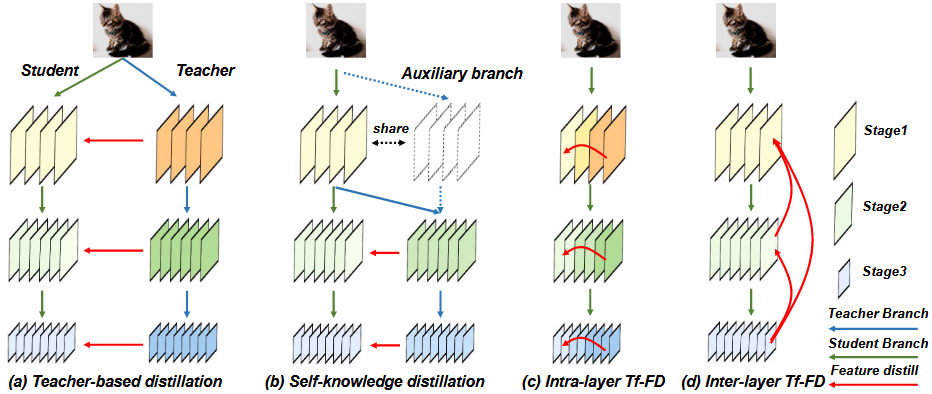
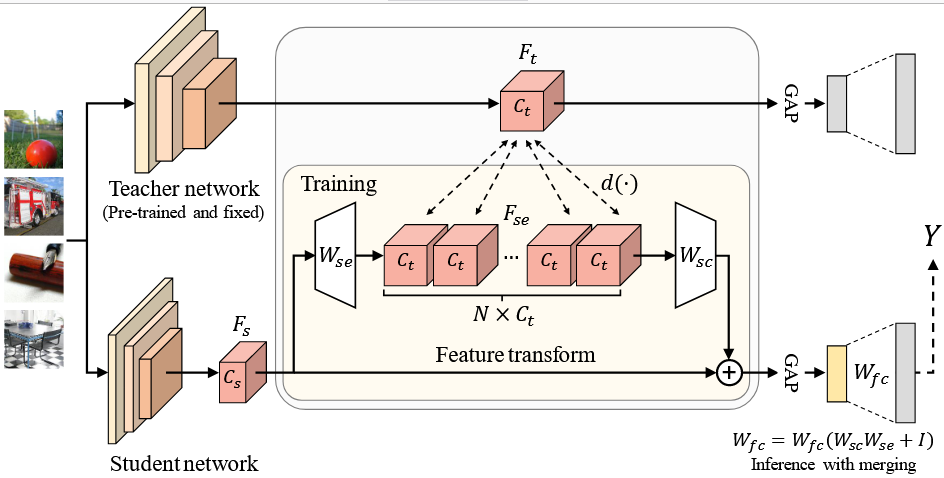
Knowledge Distillation: Tf-FD (ECCV'22), SHAKE (NeurIPS'22), NORM (ICLR'23)
I am/was the Area Chair for ICLR'25, NeurIPS'25, ACM-MM'25, BMCV'24 and more. I am awarded the Ant InTech Scholarship–Future and DAAD NeT-AI Fellowship-2024.
I'll be at AAAI 26 in Singapore (Jan 20 – 27th) in person—happy to chat!
News: Two papers accepted by AAAI'26 and One papers accepted by ACM-MM'25 (on MoE and Merged LLMs ):
News: Two papers accepted by ICCV'25 and there papers accepted by ICML'25 (on Efficient MoE LLMs):
Selected Preprints: